A git branching model for 15 people sharing a single testing environment
My development team collaborates every day with a QA team to ship timely well-tested work. We work on a feature and put it up for testing; if QA passes it, we prepare it for production. Every week, after QAs perform full regression testing, we deploy to production (occasionally, they spot tricky bugs or regressions that we fix or revert).
A typical workflow, but with a caveat: we share a single testing environment (and thus git branch), which complicates preparing releases: either the shared branch contains untested code, or developers wait on QA and on each other to merge after acceptance. We tried for long to solve this from scratch by provisioning more testing environments, so that developers and QA work in parallel while the shared branch only contains tested work, but in vain: we depend on a third party that so far can’t provision extra testing environments (an Electronic Health Record –EHR– company).
How does this team of 12 developers and 3 QAs get their work tested on the one shared environment, deploy only acceptance-tested work weekly, without code freezes?
Solution zero: GitHub flow with two Epion testing environments
To ensure we’d test everything before deployments, we had two Epion testing environments (connected to our single EHR account) where we’d test branches before merge. Merging after tests guaranteed the shared branch only contained accepted work and was always deployable (the simple GitHub flow).
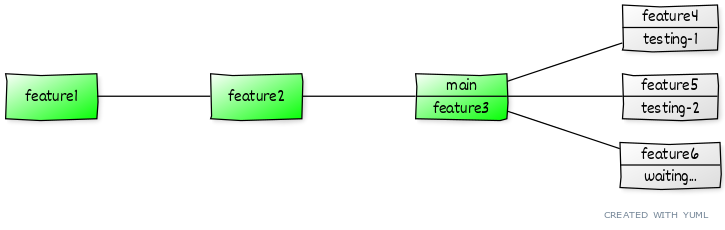 Commits for features 4 and 5 are on both testing environments; feature 6 awaits its turn for testing.
Commits for features 4 and 5 are on both testing environments; feature 6 awaits its turn for testing.
Two environments didn’t suffice, and we went up to four, but having them all connected to the same EHR account meant changes from one could affect others, and we started seeing more unexpected errors due to the invisible shared context. Also, we grew past four parallel lines of work.
We needed to go back to a single testing environment but still guarantee we wouldn’t block each other, and we’d release only tested work.
First solution: Parallel branches
We devised a cherry-pick based git workflow with two parallel branches:
developcontains all commits ready for testing. Developers merge into this branch as soon as code review passes; QA tests them in our single testing environment.maincontains all QA-accepted commits. Developers cherry-pick when their work is accepted, except on regression days whenmaingets frozen, and they need to wait.
In theory, develop was a superset of main that contained all work ready for deployment plus some untested work. When we had a handful of cards in development that we could easily track in our minds, that was true, but that didn’t hold once the team grew.
For a card requiring follow-up commits, the developer may forget to cherry-pick all of them once accepted. Or a dev-only kind of task (sometimes dependency upgrades) would be invisible to QA. We’d apply it to develop and forget to port it over to main, erroneously believing that the production version of our code had the commit. As branches diverged for long, it got harder to spot such differences.
 Features 4, 1, and 2 were accepted and cherry-picked (copied) into
Features 4, 1, and 2 were accepted and cherry-picked (copied) into main.
Other issues with this workflow:
- Deploying any work to production involved committing twice
- The team needed reminders to move accepted cards over to
main - Occasionally we’d wait for a commit that needed to go out that week, delaying regression testing and resulting in long workdays for QA
- Irrelevant merge conflicts arose due to different commits order on each branch
- The process’ complexity prompted more questions, like:
- Do we squash fixups in main, so it ends up being a single, revertable commit?
- How do I know when
mainis frozen, or can I commit now? - Do we cherry-pick from the feature branch we worked on or from
develop?
As we started developing more projects in parallel, we needed to decouple deployments from testing. Our work is accepted straight out of the bat two-thirds of the time. Developers should forget their work as soon as they merge, two-thirds of the times.
The new proposal: Weekly release cuts
We “cut a release” every Tuesday at midday, no questions asked (even with not-yet-accepted commits). That day QA focuses on the untested cards that made it into the cut, so on regression and deploy day, all cards are Accepted (or reverted) as was guaranteed by our previous workflow. We run deployments the following day.
If a developer merges work after midday, it will miss the week’s “deploy train” and appear on the following week’s release (features 4 and 5 in the diagram).
 Release cut on feature3 by moving
Release cut on feature3 by moving main onto it; develop continued moving forward. QA tests feature1 and 3 first.
Advantages over the first solution:
- The happy path is “don’t make me think” simple. If a card gets accepted, it will reach production in less than a week
- Developers don’t need to interact with
main(unless preparing a deployment or they need to revert) - QA can start regression testing a day before, decreasing the chance of rushed deploy days
- No code freezes; developers can always merge their work
Given we cut the release a day (instead of hours) before regression testing starts, develop usually contains Accepted commits during deploy day that won’t go out to production until the following week. The clear deadline has forced developers to try getting their priority work earlier in the sprint to maximize the chance to see production on time, alleviating the QA team’s work.
But we rarely have such urgent tasks. This process helped us see that a commit can go out next week even when ready today, which is not a problem for our teams or clients as we used to feel.
When we need a task out the door after the release cut time, we perform a smaller deployment the next day with that commit (with scoped down, faster regression testing) or postpone regression testing and deployment one day.
As a disadvantage, if QA rejects a card that made it into the release, the developer must revert the commit from main or prepare a (risky?) fixup. Our first solution specified reverts too, but we usually added fixup commits instead, given parallel develop wasn’t under pressure. We began using more feature flags to turn off features dynamically, mitigating the need for git revert. A good practice for sure, but our team didn’t feel the need for them before and gladly incorporated them.
This solution is closer to git-flow but:
- Without release branches. We maintain a single version: the one that currently runs in production, so “release” and “main” mean the same thing for us (we don’t need to backport bugfixes)
- Adding our definition of when develop “reaches a stable point and is ready to be released”. The first solution was “never”, and now it’s when we merge to
mainand ask QA to prioritize untested cards in it.
We’ve been running on this new workflow for a couple of months now. QA regression testing isn’t as rushed as before; we know all commits we intend for production are there; developers don’t need to wait to merge, or double-commit all their work.
If you find yourself in the unlucky position of needing to share fewer testing environments than lines of work, give this git workflow a try, it may help your team too.